.png)


What Are Convolutional Neural Networks (CNNs)? Imagine a machine that can see the world as we do—recognizing faces, identifying objects, and even understanding the context of a scene. That’s essentially what Convolutional Neural Networks (CNNs) do. But what is convolution neural networks, and why are they so important in AI?
CNNs are a special type of deep learning model designed to analyze visual data, like images and videos, by detecting patterns and features, such as edges, shapes, and colors. Inspired by how the human brain processes visual information, CNNs have become the go-to technology for solving some of the most challenging problems in artificial intelligence.Why Should You Care About CNNs?
If you’ve ever used facial recognition to unlock your phone, browsed products recommended based on images, or heard about AI diagnosing diseases from X-rays, you’ve already seen CNNs in action.
The convolutional neural network in AI is a powerhouse, making tasks like image recognition, object detection, and video analysis not just possible but remarkably accurate. Beyond images, CNNs are finding applications in areas like forecasting, natural language processing, and more.How CNNs Work
Convolutional Neural Networks (CNNs) are designed to automatically and adaptively learn patterns from data, making them incredibly powerful tools for tasks like image classification, object detection, and even video analysis.
Understanding how CNNs work involves looking at the key steps in the process, from input to output, and appreciating the role of the various layers that make up the network. Let’s break it down step by step. Step-by-Step Workflow1. Data Input (Image Representation as a Matrix)
The first step in a CNN is the input stage. Here, an image (or any other type of data) is fed into the network. However, the computer doesn't see the image the way we do. It represents the image as a matrix of numbers, where each number corresponds to a pixel value.
For color images, the matrix typically has three channels—one for red, one for green, and one for blue (RGB), with each channel holding numerical values that represent the intensity of each color at each pixel. The matrix is the raw form of the image that CNNs will work with.
Source- https://images.app.goo.gl/pkFR8UQJzBDvDhDD8
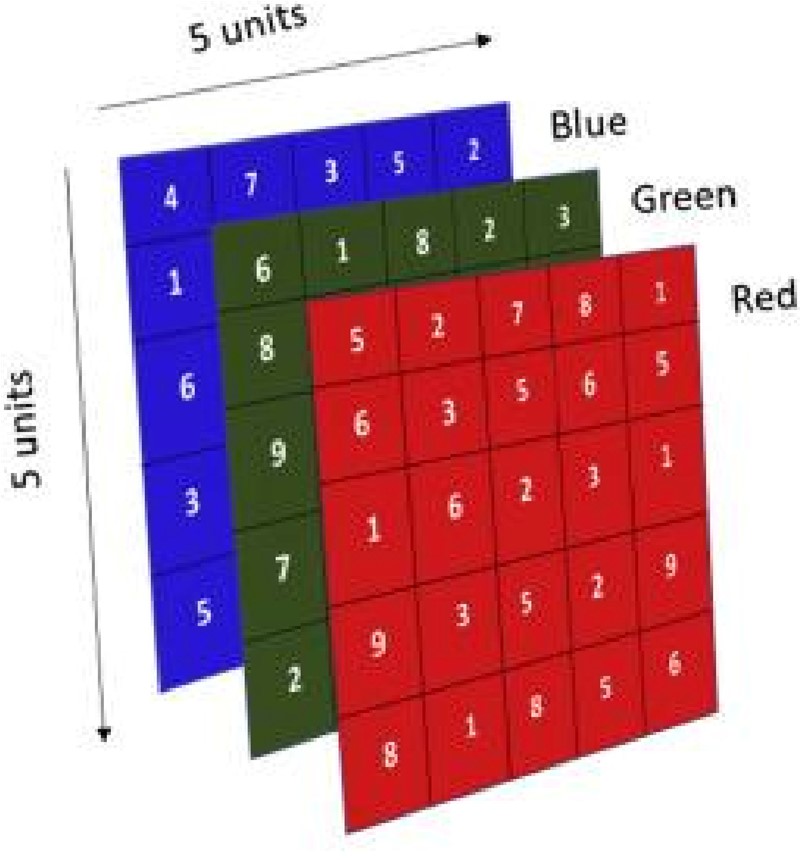
Source- https://images.app.goo.gl/Qwoiq6hDJGe77fmD9
2. Feature Extraction and Transformation
Once the image is in a numerical format, the next step is feature extraction. This is where the magic of CNNs happens. CNNs use specialized filters (also known as kernels) to scan the image and detect features such as edges, textures, and shapes. The filters move across the image, performing a mathematical operation known as convolution.
Convolution essentially involves multiplying the values in the filter by the values in the image, summing them up, and producing a new value. This process is repeated across the entire image to create what’s called a feature map.
These feature maps in CNN are crucial because they represent the various patterns and structures the network has learned to recognize.
At the beginning, CNNs might detect simple patterns like edges or corners, but as the network deepens, it can detect more complex patterns like textures, shapes, or even parts of objects. This hierarchical approach is one of the reasons CNNs are so effective in image-related tasks.3. Output Generation (Classification, Detection, etc.)
After extracting features, the CNN processes these in the deeper layers to make sense of what it's seeing. Depending on the task, the CNN might produce a variety of outputs. For example, in classification, the output is a label that represents the object in the image (e.g., "cat" or "dog").
In detection, the output might include not only the object label but also the location of the object within the image (often represented as a bounding box). For other tasks like segmentation or captioning, the output could be more complex. The deeper layers of the CNN combine all the extracted features to understand the overall structure, allowing it to make accurate predictions.Architecture of Convolutional Neural Networks
The architecture of a Convolutional Neural Network (CNN) is designed to mimic how the human brain processes visual information, making it one of the most powerful tools for tasks like image recognition, classification, and object detection.
The convolutional neural networks architecture is made up of several layers, each designed to perform a specific function in extracting features, reducing complexity, and making predictions. Let’s dive deeper into the components that make up this architecture.Overview of CNN Architecture
At a high level, the architecture of a CNN consists of three main types of layers: convolutional layers, pooling layers, and fully connected layers. These layers are stacked together in a way that allows the network to automatically learn hierarchical features of the input data.
Each layer works by transforming the input in a way that allows the network to gradually learn complex patterns in the data.The architecture is designed to allow the network to focus on different regions of an image, while progressively reducing its size and complexity, all while retaining important features.
A typical CNN architecture often follows this sequence:
1. Input Layer: Takes in raw image data, typically represented as a matrix of pixel values.
2. Convolutional Layers: Extract basic features like edges, textures, and shapes.
3. Activation Layers: Apply a non-linear activation function, such as ReLU.
4. Pooling Layers: Reduce the dimensions of the data to lower complexity.
5. Fully Connected Layers: Combine extracted features to make final predictions.
6. Output Layer: Produces the final classification or detection results.
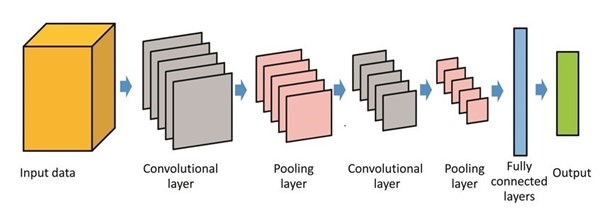
Source- https://images.app.goo.gl/fzYZNfDUhwu53GFg8
Convolution Neural Networks Layers :-1. Convolutional Layer
The convolutional layer is at the heart of CNNs and plays a crucial role in feature extraction. As the network processes an image, the convolutional layer applies a set of filters (or kernels) to the image.
These filters slide across the image, performing a mathematical operation called convolution. At each position, the filter detects a particular feature, such as an edge, a corner, or a specific texture. The result is a feature map that highlights where the detected feature appears in the image.For example, imagine a filter detecting vertical edges. As it moves across an image of a cat, the filter will respond strongly to areas where vertical edges (like the outline of the cat’s ears) are present.
This feature map then goes through the activation layer to introduce non-linearity and allow the network to learn more complex patterns.2. Pooling Layer
After features have been extracted, the pooling layer reduces the size of the feature maps while retaining important information. The goal is to reduce computational load and make the network more robust to small changes in the input data (like minor translations or rotations of objects).
There are two main types of pooling:
Max Pooling: The most common type of pooling, max pooling takes the highest value from a region in the feature map (for example, from a 2x2 area of the image). This helps retain the most important feature in that region. Average Pooling: Instead of picking the highest value, average pooling calculates the average of values in the region. This can sometimes be useful, but it may result in less sharp features compared to max pooling.Pooling helps reduce the spatial dimensions of the feature map, making the network faster and more efficient, while still keeping the most important information.
3. Fully Connected Layer
Once the network has learned a range of features through the convolutional and pooling layers, the next step is to connect those features to the final prediction. This is done in the fully connected layer.
In a fully connected layer, every neuron is connected to every neuron in the previous layer. The extracted features from the earlier layers are fed into these neurons, which combine them in various ways to make sense of the image’s overall structure.
In classification tasks, the output of this layer is used to assign a label to the input image. For example, after processing an image of a dog, the fully connected layer might output a probability that the image belongs to the class “dog” versus “cat.”4. Dropout Layer
Overfitting is a common problem in deep learning, where a model becomes too specialized to the training data and performs poorly on new, unseen data. To prevent this, CNNs often include a dropout layer.
This layer randomly "drops" (or deactivates) certain neurons during training, forcing the network to rely on different combinations of neurons for each training example.Dropout helps regularize the model, preventing it from becoming overly complex and improving its ability to generalize to new data. The dropout rate (the percentage of neurons to drop) can be adjusted based on the problem and dataset.
Code Example for CNN Architecture
Conv2D: This is the convolutional layer where the convolution operation is applied. The first argument (e.g., 32) represents the number of filters, and kernel_size=(3, 3) specifies the size of the filters.
MaxPooling2D: The pooling layer reduces the spatial dimensions of the feature map. Here, pool_size=(2, 2) means a 2x2 pool.
Flatten: This layer flattens the multi-dimensional output from the convolutional and pooling layers into a one-dimensional vector to be input into the fully connected layer.
Dense: The fully connected layer connects every neuron in the previous layer to the neurons in this layer. The final output layer uses softmax activation for multi-class classification.
Dropout: A dropout rate of 0.5 randomly deactivates 50% of the neurons during training to prevent overfitting.
Adam Optimizer: Used to minimize the loss function, which is categorical_crossentropy in this case.
This code defines a simple CNN architecture and compiles the model for training. The layers work together to learn from input images, extract meaningful features, and make predictions.
Applications of CNNs
Convolution Neural Networks (CNNs) have revolutionized the field of artificial intelligence, particularly in tasks involving image and video analysis.
Their ability to automatically learn and extract features from raw data makes them highly effective in a variety of real-world applications. Let’s explore some of the key ways CNNs are being used today.Image Recognition and Classification
One of the most prominent applications of CNNs is in image recognition and classification. This involves teaching a CNN to recognize objects, people, or scenes within an image and classify them into predefined categories.
A great example of this is facial recognition technology, which has become widely used in everything from unlocking smartphones to enhancing security systems. Facial recognition works by capturing an image of a face and passing it through a CNN that has been trained to identify facial features. The
CNN learns patterns such as the shape of eyes, nose, and mouth, and uses these features to classify the face into a database of known individuals. CNNs are incredibly effective at this task because they can learn to recognize subtle patterns that humans might miss, even in noisy or unclear images.
In addition to facial recognition, CNNs are also used in systems for recognizing other objects like cars, animals, and buildings.
For example, a CNN might be trained to distinguish between images of cats and dogs, or to identify various types of vehicles in traffic surveillance systems.
Object Detection
Another major application of CNNs is object detection, which involves not only identifying objects in an image but also determining their exact location within that image. This is particularly useful in fields such as autonomous driving, where a system needs to detect pedestrians, other vehicles, traffic signs, and more.

Other Use Cases
Beyond image recognition and object detection, CNNs are being applied in many other areas, demonstrating their versatility across different industries.
1. Medical Imaging
In the field of healthcare, CNNs are being used for medical image analysis. They help in tasks such as detecting tumors in X-rays or MRI scans, identifying abnormalities in tissue images, and even assisting in diagnosing diseases like cancer.
2. Natural Language Processing (NLP)
Although CNNs are mostly known for their work in image-based tasks, they’ve also found applications in natural language processing (NLP). In NLP, CNNs are used for tasks like sentiment analysis, where they help determine whether a sentence expresses a positive, negative, or neutral sentiment.
3. Video Analysis
CNNs are also being used in video analysis, where they help with tasks such as action recognition, face tracking, and event detection in video feeds.
4. Autonomous Vehicles
In self-driving cars, CNNs play a critical role in interpreting the visual information captured by cameras and other sensors. They help the car understand its environment by detecting road signs, pedestrians, traffic lights, and other vehicles.
Advanced Concepts in CNNs
As powerful as Convolutional Neural Networks (CNNs) are, they continue to evolve with new techniques that enhance their performance and applicability. In this section, we’ll explore some advanced concepts in CNNs, including transfer learning, hyperparameter tuning, and the challenges and limitations that come with using CNNs.
Transfer Learning: Pre-trained Models and Their Importance
One of the most exciting developments in the world of CNNs is transfer learning. This technique allows you to take a model that has already been trained on a large dataset and adapt it for a new task with much less data and time.
In traditional machine learning, training a model from scratch requires a massive amount of data and computational power. However, with transfer learning, you can leverage a pre-trained model. These models are typically trained on large, complex datasets such as ImageNet.
which contains millions of labeled images. Once trained, these models have learned to recognize a wide range of features and patterns in images. You can then fine-tune the pre-trained model to solve a new problem with a much smaller dataset by simply adjusting the last few layers of the network.
For example, imagine you need to build a model to identify different types of flowers, but you don't have a lot of labeled flower images.
Instead of training a CNN from scratch, you could use a pre-trained model like ResNet or VGG that has already learned to detect general features (like edges, textures, and shapes) from a large image dataset. You would then fine-tune the model with your smaller dataset, teaching it to classify flowers specifically.Hyperparameter Tuning: Optimizing CNN Performance
Another advanced concept in CNNs is hyperparameter tuning. Hyperparameters are settings that control how the network is trained and how it learns.
These include things like the learning rate, the number of layers, the size of the filters, the batch size, and many others. Choosing the right combination of hyperparameters is crucial for optimizing the performance of a CNN.Learning Rate: This controls how much the model’s weights are adjusted during training. Too high of a learning rate can make the model unstable, while too low can make training slow.
Number of Layers: The depth of the network, or how many layers it has, can affect how well the network learns complex features. However, deeper networks also require more data and computational resources.
Batch Size: This refers to how many samples are processed before the model’s weights are updated. Larger batch sizes can lead to faster training but might result in less accurate updates.
Hyperparameter tuning involves experimenting with different values for these parameters to find the best combination that allows the network to learn effectively and efficiently.
This process is often done through techniques like grid search (trying out a wide range of values) or random search (testing random combinations). More recently, Bayesian optimization has emerged as a more advanced technique that can automatically search for the best hyperparameters based on the model’s performance.Effective hyperparameter tuning can significantly improve CNN performance, but it also requires time and computational resources. Tools like Keras Tuner and Optuna help automate this process, making it easier to find the optimal settings for your model.
Convolutional Neural Network in Deep Learning
Convolutional Neural Networks (CNNs) are one of the most important and powerful types of neural networks in the world of deep learning.
They’ve revolutionized how machines process and understand visual data, making them a fundamental tool in fields like computer vision, image recognition, and even video analysis. Let's dive into how CNNs power deep learning and how they compare to other architectures.How CNNs Power Deep Learning
The role of CNNs in deep learning is pivotal because they enable machines to automatically learn and extract relevant features from data, especially visual data, without needing manual feature engineering.
This ability to learn hierarchies of features makes CNNs exceptionally good at solving complex problems in image and video processing.In deep learning, a convolutional neural network excels at tasks such as:
Image Classification using CNN: CNNs can look at images and identify what objects or categories are present (e.g., dog, cat, car, etc.).
Object Detection: They can not only identify an object but also determine its position in an image.
Segmentation: CNNs can even identify the exact pixel-level boundaries of objects within an image.
What makes CNNs so powerful in deep learning is their ability to learn directly from raw input data. With no need for pre-programmed features, CNNs can take in images, process them layer by layer, and gradually recognize higher-level patterns.
The deep hierarchical structure of CNNs allows them to break down an image into simple features like edges and textures in the earlier layers and more complex features like shapes or objects in deeper layers.Comparison with Other Deep Learning Architectures
While CNNs have dominated the field of computer vision, other deep learning architectures, like Recurrent Neural Networks (RNNs) and Transformers, are better suited for different types of data and tasks. Let’s compare CNNs with these architectures to understand their strengths and limitations.
1. RNNs (Recurrent Neural Networks)
Unlike CNNs, which excel in tasks involving static data like images, Recurrent Neural Networks (RNNs) are designed for sequential data.
They are especially good at processing and making predictions based on time-series data or any form of data that has an inherent order, such as text or speech.RNNs have a unique architecture where information is passed from one step of the sequence to the next, which allows them to maintain a memory of previous inputs. For example, RNNs are widely used in natural language processing (NLP) for tasks like sentiment analysis, language translation, and speech recognition.
While CNNs are focused on spatial data (like images), RNNs handle temporal or sequential data, making them ideal for tasks where the sequence of data matters, like predicting the next word in a sentence or detecting anomalies in time-series data.
2. Transformers
In recent years, Transformers have emerged as one of the most powerful deep learning models, especially in NLP tasks. Transformers are based on an attention mechanism that allows them to weigh the importance of each part of the input data, regardless of its position in the sequence.
This attention mechanism makes Transformers highly effective in tasks like machine translation, text summarization, and question answering.Compared to RNNs, Transformers don’t process data sequentially. Instead, they look at the entire input at once and determine the relationships between different parts of it. This parallel processing makes Transformers faster and more scalable, especially when dealing with large datasets.
They have also been adapted for use in other fields, including computer vision, where they are gaining traction in tasks like image classification and object detection.However, Transformers are more computationally expensive than CNNs, and CNNs are still the go-to solution for many image-based tasks due to their efficiency and specialization in visual data.
Convolutional Neural Network Interview Questions
Here are some common questions about Convolutional Neural Networks (CNNs) that can help clarify how they work and their applications.
What is the Full Form of CNN?
The full form of CNN is Convolutional Neural Network. It’s a specialized type of artificial neural network primarily used in deep learning for processing data that has a grid-like structure, such as images.
How Do CNN Layers Work?
The architecture of CNNs consists of several key layers that work together to process and analyze input data, typically images. The CNN layers work together in a sequence to extract, transform, and use the features of the input data, ultimately allowing the network to make predictions or classifications.
What Are the Best Use Cases of CNN in AI?
Some of the best use cases of CNN in AI include, Image Classification, Object Detection, Face Recognition, Medical Imaging and Video Analysis.Why Are CNNs Effective for Image Data?
CNNs are particularly effective for image data because of how they are designed to process spatial hierarchies in images. A CNN image is treated as a grid of pixels, where each pixel contains information that can be learned and processed by the network.
The convolutional layers in CNNs are able to scan these images with filters that detect local patterns such as edges, shapes, or textures.Can CNNs Be Used for Non-Image Data?
While CNNs are primarily known for image data, they can also be applied to other types of non-image data in some cases. CNNs can handle data that has a grid-like structure, where local patterns are important. For example, Text Data, Time-Series Data and Audio Data.
Conclusion
To sum it up, learning about convolutional neural networks (CNNs) can open doors to exciting opportunities in AI and deep learning. CNNs drive some of the most remarkable advancements today, from image recognition to self-driving cars and breakthroughs in healthcare.
By understanding how CNNs function and their applications, you’ll gain the skills to tackle real-world challenges and make a strong impact in the tech industry. Exploring CNNs is a valuable step for anyone looking to grow their expertise and thrive in the ever-evolving field of technology. (4).png) Call Now
Call Now